4 데이터 핸들링(Data handling)
학습 목표
- Hadely Weckam이 개발한 데이터의 전처리 및 시각화를 위해 각광받는 tidyverse 패키지에 대해 알아본다
- 데이터를 읽고, 저장하고, 목적에 맞게 가공하고, tidyverse 하에서 반복 계산 방법에 대해 알아본다.
데이터 분석과정
- 데이터를 R 작업환경(workspace)에 불러오고(import),
- 불러온 데이터를 가공하고(data management, data preprocessing),
- 가공한 데이터를 분석(analysis, modeling) 및 시각화(visualization) 후,
- 분석 결과를 저장(save) 및 외부 파일로 내보낸(export) 후,
- 이를 통해 전문가와 소통(communicate)
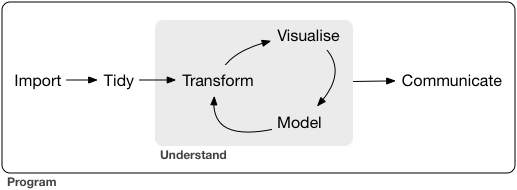
Figure 4.1: Data 분석의 과정. Wickham and Grolemund (2016) 에서 발췌
R의 데이터 가공(관리) 방법
기본 R을 활용: 지금까지 배워온 방법으로 분석을 위한 데이터 가공(색인, 필터, 병합 등)
tidyverse 패키지 활용
- 직관적 코드 작성 가능
- 빠른 실행속도
data.table 패키지 활용(본 강의에서는 다루지 않음)
- 빠른 실행속도
다양한 통계 함수와 최신 분석에 대한 여러 패키지 및 함수를 R 언어를 통해 활용 가능함에도 불구하고, 타 통계 소프트웨어(SAS, SPSS, Stata, Minitab 등)에 비해 데이터 가공 및 처리가 직관적이지 않고 불편했던 점은 R이 갖고 있던 큰 단점 중 하나임. RStudio의 수석 데이터 과학자인 Hadely Wickham의 tidyverse는 이러한 단점을 최대한 보완했고, 현재는 R을 통한 데이터 분석에서 핵심적인 도구로 자리매김 하고 있음. Tidyverse의 철학은 R 언어의 생태계에 혁신적인 변화를 가져왔을 뿐 아니라 지속적으로 진화하고 있기 때문에 해당 패키지들이 제공하는 언어 형태를 이해할 필요가 있음.
References
Wickham, Hadley, and Garrett Grolemund. 2016. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. " O’Reilly Media, Inc.".