9.3 dplyr 패키지
dplyr에서 제공하는 “동사”(함수)로 데이터(데이터 프레임) 전처리 방법에 대해 익힌다.
dplyr은 tidyverse 에서 데이터 전처리를 담당하는 패키지로 데이터 전처리 과정을 쉽고 빠르게 수행할 수 있는 함수로 구성된 패키지임.데이터 핸들링을 위해 Hadley Wickham이 개발한
plyr패키지를 최적화한 패키지로 C++ 로 코딩되어 성능이plyr에 비해 월등히 우수함.base R에 존재하는 함수만으로도 전처리는 충분히 가능하나,
dplyr은 아래와 같은 장점을 가짐파이프 연산자(
%>%)로 코드의 가독성 극대화코드 작성이 쉬움
- 전통적인 R의 데이터 처리에서 사용되는
[,[[,$와 같은 색인 연산자 최소화 dplyr은 몇 가지 “동사”를 조합하여 사용
- 전통적인 R의 데이터 처리에서 사용되는
RStudio를 사용할 경우 코드 작성이 빨라짐
접근 방법이 SQL 문과 유사함
dplyr은 초기 데이터 프레임만을 다루지만,purrr패키지를 통해 행렬, 배열, 리스트 등에도 적용 가능dplyr에서 제공하는 가장 기본 “동사”는 다음과 같음filter(): 각 행(row)을 조건에 따라 선택arrange(): 선택한 변수(column)에 해당하는 행(row)을 기준으로 정렬select(): 변수(column) 선택mutate(): 새로운 변수를 추가하거나 이미 존재하는 변수를 변환summarize()또는summarise(): 변수 집계(평균, 표준편차, 최댓값, 최솟값, …)group_by(): 위 열거한 모든 동사들을 그룹별로 적용
base R 제공 함수와 비교
| 동사(함수) | 내용 | R base 패키지 함수 |
|---|---|---|
| filter() | 행 추출 | subset() |
| arrange() | 내림차순/오름차순 정렬 | order(), sort() |
| select() | 열 선택 | data[, c(‘var_name01’, ‘var_name03’)] |
| mutate() | 열 추가 및 변환 | transform() |
| summarise() | 집계 | aggregate() |
| group_by() | 그룹별 집계 및 함수 적용 |
dplyr기본 동사와 연동해서 사용되는 주요 함수slice(): 행 색인을 이용한 추출 \(\rightarrow\)data[n:m, ]과 동일distinct(): 행 레코드 중 중복 항복 제거 \(\rightarrow\) base R 패키지의unique()함수와 유사sample_n(),sample_frac(): 데이터 레코드를 랜덤하게 샘플링rename(): 변수명 변경inner_join,right_join(),left_join(),full_join: 두 데이터셋 병합 \(\rightarrow\)merge()함수와 유사tally(),count(),n(): 데이터셋의 행의 길이(개수)를 반환하는 함수로 (그룹별) 집계에 사용:length(),nrow()/NROW()함수와 유사*_all,,*_at,*_if:dplyr에서 제공하는 기본 동사(group_by()제외) 사용 시 적용 범위를 설정해 기본 동사와 동일한 기능을 수행하는 함수
filter() 함수는 시계열 데이터의 노이즈를 제거하는 함수이지만, tidyverse 패키지를 읽어온 경우, dplyr 패키지의 filter() 함수와 이름이 중복되기 때문에 R 작업공간 상에서는 dplyr 패키지의 filter()가 작동을 함. 만약 stats 패키지의 filter() 함수를 사용하고자 하면 stats::filter()를 사용. 이를 더 일반화 하면 현재 컴퓨터 상에 설치되어 있는 R 패키지의 특정 함수는 :: 연산자를 통해 접근할 수 있으며, package_name::function_name() 형태로 접근 가능함.
9.3.1 파이프 연산자: %>%
Tidyverse 세계에서 tidy를 담당하는 핵심적인 함수
여러 함수를 연결(chain)하는 역할을 하며, 이를 통해 불필요한 임시변수를 정의할 필요가 없어짐
function_1(x) %>% function_2(y) = function_2(function_1(x), y):function_1(x)에서 반환한 값을function_2()의 첫 번째 인자로 사용x %>% f(y) %>% g(z)= ?기존 R 문법과 차이점
- 기존 R: 동사(목적어, 주변수, 나머지 변수)
- Pipe 연결 방식: 목적어
%>%동사(주변수, 나머지 변수)
예시
# base R 문법 적용
print(head(iris, 4)) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa# %>% 연산자 이용
iris %>% head(4) %>% print Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa# setosa 종에 해당하는 변수들의 평균 계산
apply(iris[iris$Species == "setosa", -5], 2, mean)Sepal.Length Sepal.Width Petal.Length Petal.Width
5.006 3.428 1.462 0.246 # tidyverse의 pipe 연산자 이용
# require(tidyverse)
iris %>%
filter(Species == "setosa") %>%
select(-Species) %>%
summarise_all(mean)# Homework #3 b-c 풀이를 위한 pipe 연산 적용
# df <- within(df, {
# am <- factor(am, levels = 0:1,
# labels = c("automatic", "manual"))
# })
# ggregate(cbind(mpg, disp, hp, drat, wt, qsec) ~ am,
# data = df,
# mean)
# aggregate(cbind(mpg, disp, hp, drat, wt, qsec) ~ am,
# data = df,
# sd)
mtcars %>%
mutate(am = factor(vs,
levels = 0:1,
labels = c("automatic", "manual"))) %>%
group_by(am) %>%
summarise_at(vars(mpg, disp:qsec),
list(mean = mean,
sd = sd))9.3.2 filter()
행(row, case, observation) 조작 동사
- 데이터 프레임(또는 tibble)에서 특정 조건을 만족하는 레코드(row) 추출

Figure 9.2: filter() 함수 다이어그램
R base 패키지의
subset()함수와 유사하게 작동하지만 성능이 더 좋음(속도가 더 빠르다).추출을 위한 조건은 2.2.4 절 논리형 스칼라에서 설명한 비교 연산자를 준용함. 단
filter()함수 내에서 and (&) 조건은,(콤마, comma)로 표현 가능filter()에서 가능한 불린(boolean) 연산
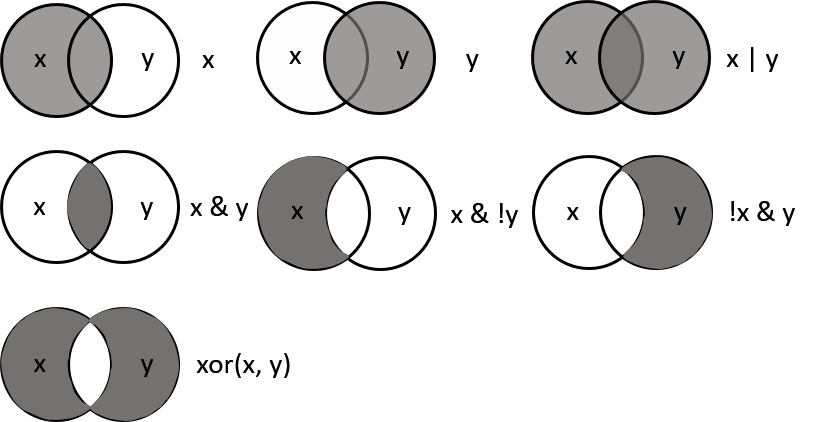
Figure 9.3: 가능한 모든 boolean 연산 종류: x는 좌변, y는 우변을 의미하고 음영은 연산 이후 선택된 부분을 나타냄.
# filter() 동사 prototype
dplyr::filter(x, # 데이터 프레임 또는 티블 객체
condition_01, # 첫 번째 조건
condition_02, # 두 번째 조건
# 두 번째 인수 이후 조건들은
# condition_1 & condition 2 & ... & condition_n 임
...)예시 1:
mpg데이터(ggplot2패키지 내장 데이터)mpg데이터 코드북- 데이터 구조 확인을 위해 dplyr 패키지에서 제공하는
glimpse()함수(str()유사) 사용
| 변수명 | 변수설명(영문) | 변수설명(국문) |
|---|---|---|
| manufacturer | manufacturer name | 제조사 |
| model | model name | 모델명 |
| displ | engine displacement, in litres | 배기량 (리터) |
| year | year of manufacture | 제조년도 |
| cyl | number of cylinders | 엔진 기통 수 |
| trans | type of transmission | 트렌스미션 |
| drv | the type of drive train, where f = front-wheel drive, r = rear wheel drive, 4 = 4wd | 구동 유형: f = 전륜구동, r = 후륜구동, 4 = 4륜 구동 |
| cty | city miles per gallon | 시내 연비 |
| hwy | highway miles per gallon | 고속 연비 |
| fl | fuel type: e = E85, d = diesel, r = regular, p = premium, c = CNG | 연료: e = 에탄올 85, r = 가솔린, p = 프리미엄, d = 디젤, c = CNP |
| class | ‘type’ of car | 자동차 타입 |
glimpse(mpg)Rows: 234
Columns: 11
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto…
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "c…# 현대 차만 추출
## 기본 문법 사용
# mpg[mpg$manufacturer == "hyundai", ]
# subset(mpg, manufacturer == "hyundai")
## filter() 함수 사용
# filter(mpg, manufacturer == "hyundai")
## pipe 연산자 사용
mpg %>%
filter(manufacturer == "hyundai")# 시내 연비가 20 mile/gallon 이상이고 타입이 suv 차량 추출
## 기본 문법 사용
# mpg[mpg$cty >= 20 & mpg$class == "suv", ]
# subset(mpg, cty >= 20 & class == "suv")
## filter() 함수 사용
# filter(mpg, cty >= 20, class == "suv")
## pipe 연산자 사용
mpg %>%
filter(cty >= 20,
class == "suv")# 제조사가 audi 또는 volkswagen 이고 고속 연비가 30 miles/gallon 인 차량만 추출
mpg %>%
filter(manufacturer == "audi" | manufacturer == "volkswagen",
hwy >= 30)9.3.3 arrange()
행(row, case, observation) 조작 동사
지정한 열을 기준으로 데이터의 레코드(row)를 오름차순(작은 값부터 큰 값)으로 정렬
내림차순(큰 값부터 작은 값) 정렬 시
desc()함수 이용

Figure 9.4: arrange() 함수 다이어그램
arrange(data, # 데이터 프레임 또는 티블 객체
var1, # 기준 변수 1
var2, # 기준 변수 2
...)- 예시 1:
mpg데이터셋
# 시내 연비를 기준으로 오름차순 정렬
## R 기본 문법 사용
# mpg[order(mpg$cty), ]
## arrange 함수 사용
# arrange(mpg, cty)
## pipe 사용
mpg_asc <- mpg %>% arrange(cty)
mpg_asc %>% print# A tibble: 234 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 dodge dakota pi… 4.7 2008 8 auto… 4 9 12 e pick…
2 dodge durango 4… 4.7 2008 8 auto… 4 9 12 e suv
3 dodge ram 1500 … 4.7 2008 8 auto… 4 9 12 e pick…
4 dodge ram 1500 … 4.7 2008 8 manu… 4 9 12 e pick…
5 jeep grand che… 4.7 2008 8 auto… 4 9 12 e suv
6 chevrolet c1500 sub… 5.3 2008 8 auto… r 11 15 e suv
7 chevrolet k1500 tah… 5.3 2008 8 auto… 4 11 14 e suv
8 chevrolet k1500 tah… 5.7 1999 8 auto… 4 11 15 r suv
9 dodge caravan 2… 3.3 2008 6 auto… f 11 17 e mini…
10 dodge dakota pi… 5.2 1999 8 manu… 4 11 17 r pick…
# ℹ 224 more rows# 시내 연비는 오름차순, 차량 타입은 내림차순(알파벳 역순) 정렬
## R 기본 문법 사용
### 문자형 벡터의 순위 계산을 위해 rank() 함수 사용
mpg_sortb <- mpg[order(mpg$cty, -rank(mpg$class)), ]
## arrange 함수 사용
mpg_sortt <- mpg %>% arrange(cty, desc(class))
mpg_sortt %>% print# A tibble: 234 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 dodge durango 4… 4.7 2008 8 auto… 4 9 12 e suv
2 jeep grand che… 4.7 2008 8 auto… 4 9 12 e suv
3 dodge dakota pi… 4.7 2008 8 auto… 4 9 12 e pick…
4 dodge ram 1500 … 4.7 2008 8 auto… 4 9 12 e pick…
5 dodge ram 1500 … 4.7 2008 8 manu… 4 9 12 e pick…
6 chevrolet c1500 sub… 5.3 2008 8 auto… r 11 15 e suv
7 chevrolet k1500 tah… 5.3 2008 8 auto… 4 11 14 e suv
8 chevrolet k1500 tah… 5.7 1999 8 auto… 4 11 15 r suv
9 dodge durango 4… 5.2 1999 8 auto… 4 11 16 r suv
10 dodge durango 4… 5.9 1999 8 auto… 4 11 15 r suv
# ℹ 224 more rows# 두 데이터 셋 동일성 여부
identical(mpg_sortb, mpg_sortt)[1] TRUE9.3.4 select()
열(변수) 조작 동사
- 데이터셋을 구성하는 열(column, variable)을 선택하는 함수

Figure 5.5: select() 함수 다이어그램
select(
data, # 데이터 프레임 또는 티블 객체
var_name1, # 변수 이름 (따옴표 없이도 가능)
var_name2,
...
)# 제조사(manufacturer), 모델명(model), 배기량(displ)
# 제조년도(year), 시내연비 (cty)만 추출
## 기본 R 문법 이용한 변수 추출
glimpse(mpg[, c("manufacturer", "model", "displ", "year", "cty")])Rows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…# glimpse(mpg[, c(1:4, 8)])
# glimpse(mpg[, names(mpg) %in% c("manufacturer", "displ", "model",
# "year", "cty")])
## select() 함수 이용
### 아래 스크립트는 모두 동일한 결과를 반환
# mpg %>% select(1:4, 8)
#
# mpg %>%
# select(c("manufacturer", "model", "displ", "year", "cty"))
mpg %>%
select("manufacturer", "model", "displ", "year", "cty") %>%
glimpseRows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…R 기본 문법과 차이점
- 선택하고자 하는 변수 입력 시 따옴표가 필요 없음
:연산자를 이용해 선택 변수의 범위 지정 가능-연산자를 이용해 선택 변수 제거
# 제조사(manufacturer), 모델명(model), 배기량(displ)
# 제조년도(year), 시내연비 (cty)만 추출
## select() 따옴표 없이 변수명 입력
mpg %>%
select(manufacturer, model, displ, year, cty) %>%
glimpseRows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…## : 연산자로 변수 범위 지정
mpg %>%
select(manufacturer:year, cty) %>%
glimpseRows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…## 관심 없는 열을 -로 제외 가능
mpg %>%
select(-cyl, -trans, -drv, -hwy, -fl, -class) %>%
glimpseRows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…## 조금 더 간결하게 (`:`와 `-` 연산 조합)
mpg %>%
select(-cyl:-drv, -hwy:-class) %>%
glimpseRows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…### 동일한 기능: -는 괄호로 묶을 수 있음
mpg %>%
select(-(cyl:drv), -(hwy:class)) %>%
glimpseRows: 234
Columns: 5
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…# select() 함수를 이용해 변수명 변경 가능
mpg %>%
select(city_mpg = cty) %>%
glimpseRows: 234
Columns: 1
$ city_mpg <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 15, 1…select()와 조합 시 유용한 선택 함수starts_with("abc"): “abc”로 시작하는 변수 선택ends_with("xyz"): “xyz”로 끝나는 변수 선택contains("def"): “def”를 포함하는 변수 선택matches("^F[0-9]"): 정규표현식과 일치하는 변수 선택. “F”와 한 자리 숫자로 시작하는 변수 선택everything():select()함수 내에서 미리 선택한 변수를 제외한 모든 변수 선택
# "m"으로 시작하는 변수 제거
## 기존 select() 함수 사용
mpg %>%
select(-manufacturer, -model) %>%
glimpseRows: 234
Columns: 9
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.8, 2.8,…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 2008, 2008…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, 8, 8, 8…
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto(l5)", …
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4", "4",…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 15, 15, …
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 25, 24, …
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p",…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "compact"…## select() + starts_with() 함수 사용
mpg %>%
select(-starts_with("m")) %>%
glimpseRows: 234
Columns: 9
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.8, 2.8,…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 2008, 2008…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, 8, 8, 8…
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto(l5)", …
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4", "4",…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 15, 15, …
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 25, 24, …
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p",…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "compact"…# "l"로 끝나는 변수 선택: ends_with() 함수 사용
mpg %>%
select(ends_with("l")) %>%
glimpseRows: 234
Columns: 4
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "a4 quat…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.8, 2.8,…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, 8, 8, 8…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p",…# dplyr 내장 데이터: starwars에서 이름, 성별, "color"를 포함하는 변수 선택
## contains() 함수 사용
starwars %>%
select(name, gender, contains("color")) %>%
head# 다시 mpg 데이터...
## 맨 마지막 문자가 "y"로 끝나는 변수 선택(제조사, 모델 포함)
## matches() 사용
mpg %>%
select(starts_with("m"), matches("y$")) %>%
glimpseRows: 234
Columns: 4
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…# cty, hwy 변수를 각각 1-2 번째 열에 위치
mpg %>%
select(matches("y$"), everything()) %>%
glimpseRows: 234
Columns: 11
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto…
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "c…9.3.5 mutate()
열(변수) 조작 동사: 새로운 열을 추가하는 함수로 기본 R 문법의
data$new_variable <- value와 유사한 기능을 함
- 주어진 데이터 셋(데이터 프레임)에 이미 존재하고 있는 변수를 이용해 새로운 값 변환 시 유용
- 새로 만든 열을
mutate()함수 내에서 사용 가능 \(\rightarrow\) R base 패키지에서 재공하는transform()함수는mutate()함수와 거의 동일한 기능을 하지만,transform()함수 내에서 생성한 변수의 재사용이 불가능

Figure 9.5: mutate() 함수 다이어그램
# mpg 데이터 셋의 연비 단위는 miles/gallon으로 입력 -> kmh/l 로 변환
mile <- 1.61 #km
gallon <- 3.79 #litres
kpl <- mile/gallon
## 기본 R 문법
glimpse(transform(mpg,
cty_kpl = cty * kpl,
hwy_kpl = hwy * kpl))Rows: 234
Columns: 13
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto…
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "c…
$ cty_kpl <dbl> 7.646438, 8.920844, 8.496042, 8.920844, 6.796834, 7.64643…
$ hwy_kpl <dbl> 12.319261, 12.319261, 13.168865, 12.744063, 11.044855, 11…## tidyverse 문법
mpg %>%
mutate(cty_kpl = cty*kpl,
hwy_kpl = hwy*kpl) %>%
glimpseRows: 234
Columns: 13
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto…
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "c…
$ cty_kpl <dbl> 7.646438, 8.920844, 8.496042, 8.920844, 6.796834, 7.64643…
$ hwy_kpl <dbl> 12.319261, 12.319261, 13.168865, 12.744063, 11.044855, 11…# 새로 생성한 변수를 이용해 변환 변수를 원래 단위로 바꿔보기
## R 기본 문법: transform() 사용
glimpse(transform(mpg,
cty_kpl = cty * kpl,
hwy_kpl = hwy * kpl,
cty_raw = cty_kpl/kpl,
hwy_raw = hwy_kpl/kpl,
)) Error in eval(substitute(list(...)), `_data`, parent.frame()): 객체 'cty_kpl'를 찾을 수 없습니다## Tidyverse 문법
mpg %>%
mutate(cty_kpl = cty*kpl,
hwy_kpl = hwy*kpl,
cty_raw = cty_kpl/kpl,
hwy_raw = hwy_kpl/kpl) %>%
glimpseRows: 234
Columns: 15
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto…
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "c…
$ cty_kpl <dbl> 7.646438, 8.920844, 8.496042, 8.920844, 6.796834, 7.64643…
$ hwy_kpl <dbl> 12.319261, 12.319261, 13.168865, 12.744063, 11.044855, 11…
$ cty_raw <dbl> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy_raw <dbl> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…9.3.6 transmute()
열(변수) 조작 동사: mutate()와 유사한 기능을 하지만 추가 또는 변환된 변수만 반환
`연비` <- mpg %>%
transmute(cty_kpl = cty*kpl,
hwy_kpl = hwy*kpl,
cty_raw = cty_kpl/kpl,
hwy_raw = hwy_kpl/kpl)
`연비` %>% print# A tibble: 234 × 4
cty_kpl hwy_kpl cty_raw hwy_raw
<dbl> <dbl> <dbl> <dbl>
1 7.65 12.3 18 29
2 8.92 12.3 21 29
3 8.50 13.2 20 31
4 8.92 12.7 21 30
5 6.80 11.0 16 26
6 7.65 11.0 18 26
7 7.65 11.5 18 27
8 7.65 11.0 18 26
9 6.80 10.6 16 25
10 8.50 11.9 20 28
# ℹ 224 more rows9.3.7 summarise()
변수 요약 및 집계: 변수를 집계하는 함수로 R stat 패키지(R 처음 실행 시 기본으로 불러오는 패키지 중 하나)의
aggregate()함수와 유사한 기능을 함
- 보통
mean(),sd(),var(),median(),min(),max()등 요약 통계량을 반환하는 함수와 같이 사용 - 데이터 프레임(티블) 객체 반환
- 변수의 모든 레코드에 집계 함수를 적용하므로
summarise()만 단일로 사용하면 1개의 행만 반환

Figure 9.6: summarise() 함수 다이어그램
# cty, hwy의 평균과 표준편차 계산
mpg %>%
summarise(mean_cty = mean(cty),
sd_cty = sd(cty),
mean_hwy = mean(hwy),
sd_hwy = sd(hwy))9.3.8 group_by()
행(row, case, observation) 그룹화
- 보통
summarise()함수는aggregate()함수와 유사하게 그룹 별 요약 통계량을 계산할 때 주로 사용됨 group_by()는 “주어진 그룹에 따라(by group)”, 즉 지정한 그룹(변수) 별 연산을 지정
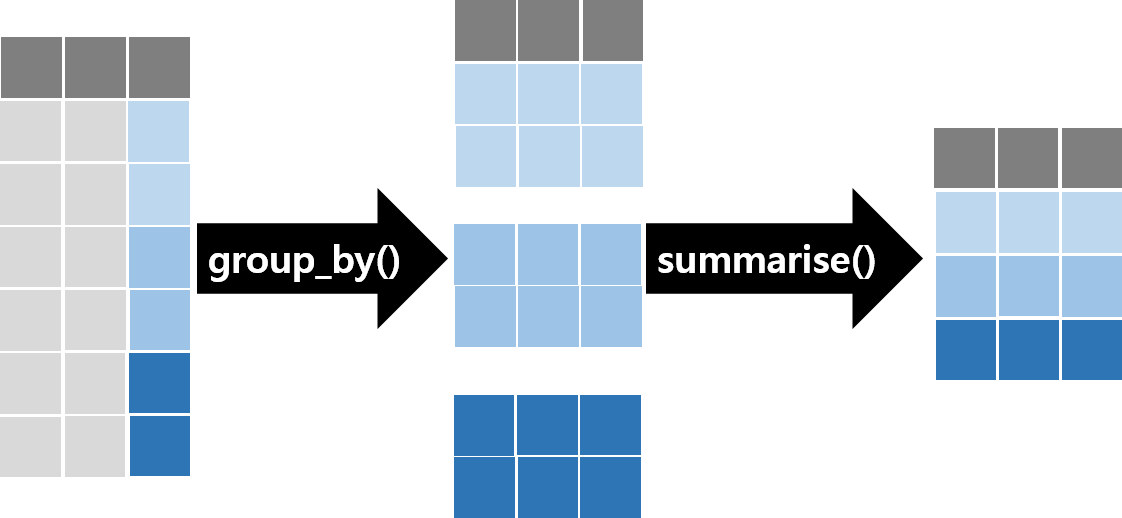
Figure 7.2: group_by() 함수 다이어그램
# 모델, 년도에 따른 cty, hwy 평균 계산
by_mpg <- group_by(mpg, model, year)
## 그룹 지정 check
by_mpg %>%
head %>%
print# A tibble: 6 × 11
# Groups: model, year [2]
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…## 통계량 계산
by_mpg %>%
summarise(mean_cty = mean(cty),
mean_hwy = mean(hwy)) %>%
print`summarise()` has grouped output by 'model'. You can override using the
`.groups` argument.# A tibble: 76 × 4
# Groups: model [38]
model year mean_cty mean_hwy
<chr> <int> <dbl> <dbl>
1 4runner 4wd 1999 15.2 19
2 4runner 4wd 2008 15 18.5
3 a4 1999 18.2 27.5
4 a4 2008 19.7 29.3
5 a4 quattro 1999 16.5 25.2
6 a4 quattro 2008 17.8 26.2
7 a6 quattro 1999 15 24
8 a6 quattro 2008 16.5 24
9 altima 1999 20 28
10 altima 2008 21 29
# ℹ 66 more rows## by_group() chain 연결
mean_mpg <- mpg %>%
group_by(model, year) %>%
summarise(mean_cty = mean(cty),
mean_hwy = mean(hwy)) group_by()이후 적용되는 동사는 모두 그룹 별 연산 수행
# 제조사 별 시내연비가 낮은 순으로 정렬
audi <- mpg %>%
group_by(manufacturer) %>%
arrange(cty) %>%
filter(manufacturer == "audi")
audi %>% print# A tibble: 18 × 11
# Groups: manufacturer [1]
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 quattro 2.8 1999 6 auto… 4 15 25 p comp…
2 audi a4 quattro 3.1 2008 6 manu… 4 15 25 p comp…
3 audi a6 quattro 2.8 1999 6 auto… 4 15 24 p mids…
4 audi a4 2.8 1999 6 auto… f 16 26 p comp…
5 audi a4 quattro 1.8 1999 4 auto… 4 16 25 p comp…
6 audi a6 quattro 4.2 2008 8 auto… 4 16 23 p mids…
7 audi a4 quattro 2.8 1999 6 manu… 4 17 25 p comp…
8 audi a4 quattro 3.1 2008 6 auto… 4 17 25 p comp…
9 audi a6 quattro 3.1 2008 6 auto… 4 17 25 p mids…
10 audi a4 1.8 1999 4 auto… f 18 29 p comp…
11 audi a4 2.8 1999 6 manu… f 18 26 p comp…
12 audi a4 3.1 2008 6 auto… f 18 27 p comp…
13 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
14 audi a4 quattro 2 2008 4 auto… 4 19 27 p comp…
15 audi a4 2 2008 4 manu… f 20 31 p comp…
16 audi a4 quattro 2 2008 4 manu… 4 20 28 p comp…
17 audi a4 1.8 1999 4 manu… f 21 29 p comp…
18 audi a4 2 2008 4 auto… f 21 30 p comp…ungroup() 함수를 사용
9.3.9 dplyr 관련 유용한 함수
- 데이터 핸들링 시 dplyr 기본 함수와 같이 사용되는 함수 모음
slice()
행(row, case, observation) 조작 동사:
filter()의 특별한 케이스로 데이터의 색인을 직접 설정하여 원하는 row 추출
# 1 ~ 8행에 해당하는 데이터 추출
slice_mpg <- mpg %>% slice(1:8)
slice_mpg %>% print# A tibble: 8 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(… f 18 29 p comp…
2 audi a4 1.8 1999 4 manua… f 21 29 p comp…
3 audi a4 2 2008 4 manua… f 20 31 p comp…
4 audi a4 2 2008 4 auto(… f 21 30 p comp…
5 audi a4 2.8 1999 6 auto(… f 16 26 p comp…
6 audi a4 2.8 1999 6 manua… f 18 26 p comp…
7 audi a4 3.1 2008 6 auto(… f 18 27 p comp…
8 audi a4 quattro 1.8 1999 4 manua… 4 18 26 p comp…# 각 모델 별 첫 번째 데이터만 추출
slice_mpg_grp <- mpg %>%
group_by(model) %>%
slice(1) %>%
arrange(model)
slice_mpg_grp %>% print# A tibble: 38 × 11
# Groups: model [38]
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 toyota 4runner 4… 2.7 1999 4 manu… 4 15 20 r suv
2 audi a4 1.8 1999 4 auto… f 18 29 p comp…
3 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
4 audi a6 quattro 2.8 1999 6 auto… 4 15 24 p mids…
5 nissan altima 2.4 1999 4 manu… f 21 29 r comp…
6 chevrolet c1500 sub… 5.3 2008 8 auto… r 14 20 r suv
7 toyota camry 2.2 1999 4 manu… f 21 29 r mids…
8 toyota camry sol… 2.2 1999 4 auto… f 21 27 r comp…
9 dodge caravan 2… 2.4 1999 4 auto… f 18 24 r mini…
10 honda civic 1.6 1999 4 manu… f 28 33 r subc…
# ℹ 28 more rowstop_n()
행(row, case, observation) 조작 동사: 선택한 변수를 기준으로 상위
n개의 데이터(행)만 추출
# mpg 데이터에서 시내 연비가 높은 데이터 5개 추출
mpg %>%
top_n(5, cty) %>%
arrange(desc(cty))distinct()
행(row, case, observation) 조작 동사: 선택한 변수를 기준으로 중복 없는 유일한(unique)한 행 추출 시 사용
- R base 패키지의
unique()또는unqiue.data.frame()과 유사하게 작동하지만 처리 속도 면에서 뛰어남
# mpg 데이터에서 중복데이터 제거 (모든 열 기준)
mpg_uniq <- mpg %>% distinct()
mpg_uniq %>% print# A tibble: 225 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto… f 18 29 p comp…
2 audi a4 1.8 1999 4 manu… f 21 29 p comp…
3 audi a4 2 2008 4 manu… f 20 31 p comp…
4 audi a4 2 2008 4 auto… f 21 30 p comp…
5 audi a4 2.8 1999 6 auto… f 16 26 p comp…
6 audi a4 2.8 1999 6 manu… f 18 26 p comp…
7 audi a4 3.1 2008 6 auto… f 18 27 p comp…
8 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
9 audi a4 quattro 1.8 1999 4 auto… 4 16 25 p comp…
10 audi a4 quattro 2 2008 4 manu… 4 20 28 p comp…
# ℹ 215 more rows# model을 기준으로 중복 데이터 제거
mpg_uniq2 <- mpg %>%
distinct(model, .keep_all = TRUE) %>%
arrange(model)
mpg_uniq2 %>% head(6) %>% print# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 toyota 4runner 4wd 2.7 1999 4 manu… 4 15 20 r suv
2 audi a4 1.8 1999 4 auto… f 18 29 p comp…
3 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
4 audi a6 quattro 2.8 1999 6 auto… 4 15 24 p mids…
5 nissan altima 2.4 1999 4 manu… f 21 29 r comp…
6 chevrolet c1500 subu… 5.3 2008 8 auto… r 14 20 r suv # 위 그룹별 slice(1) 예제와 비교
identical(slice_mpg_grp %>% ungroup, mpg_uniq2)[1] TRUEsample_n()/sample_frac()
행(row, case, observation) 조작 동사: 데이터의 행을 랜덤하게 추출하는 함수
sample_(n): 전체 \(N\) 행에서 \(n\) 행을 랜덤하게 추출sample_frac(p): 전체 \(N\) 행에서 비율 \(p\) (\(0\leq p \leq1\)) 만큼 추출
# 전체 234개 행에서 3개 행을 랜덤하게 추출
mpg %>% sample_n(3)# 전체 234개 행의 5%에 해당하는 행을 랜덤하게 추출
mpg %>% sample_frac(0.05)rename()
열(변수) 조작 동사: 변수의 이름을 변경하는 함수
rename(new_variable_name = old_variable_name)형태로 변경
# 변수명 변셩
## R 기본 문법으로 변수명 변경
varn_mpg <- names(mpg) # 원 변수명 저장
names(mpg)[5] <- "cylinder" # cyl을 cylinder로 변셩
names(mpg) <- varn_mpg #
## Tidyverse 문법: rename() 사용
mpg %>%
rename(cylinder = cyl) %>%
head %>%
print# A tibble: 6 × 11
manufacturer model displ year cylinder trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p comp…
2 audi a4 1.8 1999 4 manual(… f 21 29 p comp…
3 audi a4 2 2008 4 manual(… f 20 31 p comp…
4 audi a4 2 2008 4 auto(av) f 21 30 p comp…
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p comp…
6 audi a4 2.8 1999 6 manual(… f 18 26 p comp…## cty를 city_mpg, hwy를 hw_mpg로 변경
mpg %>%
rename(city_mpg = cty,
hw_mpg = hwy) %>%
print# A tibble: 234 × 11
manufacturer model displ year cyl trans drv city_mpg hw_mpg fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto… f 18 29 p comp…
2 audi a4 1.8 1999 4 manu… f 21 29 p comp…
3 audi a4 2 2008 4 manu… f 20 31 p comp…
4 audi a4 2 2008 4 auto… f 21 30 p comp…
5 audi a4 2.8 1999 6 auto… f 16 26 p comp…
6 audi a4 2.8 1999 6 manu… f 18 26 p comp…
7 audi a4 3.1 2008 6 auto… f 18 27 p comp…
8 audi a4 qu… 1.8 1999 4 manu… 4 18 26 p comp…
9 audi a4 qu… 1.8 1999 4 auto… 4 16 25 p comp…
10 audi a4 qu… 2 2008 4 manu… 4 20 28 p comp…
# ℹ 224 more rowstally()
- 총계, 행의 개수를 반환하는 함수11
- 데이터 프레임(티블) 객체 반환
# 전체 행 개수 (nrow(data))와 유사
mpg %>%
tally %>%
print# A tibble: 1 × 1
n
<int>
1 234# 제조사, 년도별 데이터 개수
mpg %>%
group_by(manufacturer, year) %>%
tally %>%
ungroup %>%
print# A tibble: 30 × 3
manufacturer year n
<chr> <int> <int>
1 audi 1999 9
2 audi 2008 9
3 chevrolet 1999 7
4 chevrolet 2008 12
5 dodge 1999 16
6 dodge 2008 21
7 ford 1999 15
8 ford 2008 10
9 honda 1999 5
10 honda 2008 4
# ℹ 20 more rowscount()
tally()함수와 유사하나 개수 집계 전group_by()와 집계 후ungroup()을 실행
# 제조사, 년도별 데이터 개수: tally() 예시와 비교
mpg %>%
count(manufacturer, year) %>%
print# A tibble: 30 × 3
manufacturer year n
<chr> <int> <int>
1 audi 1999 9
2 audi 2008 9
3 chevrolet 1999 7
4 chevrolet 2008 12
5 dodge 1999 16
6 dodge 2008 21
7 ford 1999 15
8 ford 2008 10
9 honda 1999 5
10 honda 2008 4
# ℹ 20 more rowsn()
- 위에서 소개한 함수와 유사하게 행 개수를 반환하지만, 기본 동사(
summarise(),mutate(),filter()) 내에서만 사용
# 제조사, 년도에 따른 배기량, 시내연비의 평균 계산(그룹 별 n 포함)
mpg %>%
group_by(manufacturer, year) %>%
summarise(
N = n(),
mean_displ = mean(displ),
mean_hwy = mean(cty)) %>%
print`summarise()` has grouped output by 'manufacturer'. You can override using the
`.groups` argument.# A tibble: 30 × 5
# Groups: manufacturer [15]
manufacturer year N mean_displ mean_hwy
<chr> <int> <int> <dbl> <dbl>
1 audi 1999 9 2.36 17.1
2 audi 2008 9 2.73 18.1
3 chevrolet 1999 7 4.97 15.1
4 chevrolet 2008 12 5.12 14.9
5 dodge 1999 16 4.32 13.4
6 dodge 2008 21 4.42 13.0
7 ford 1999 15 4.45 13.9
8 ford 2008 10 4.66 14.1
9 honda 1999 5 1.6 24.8
10 honda 2008 4 1.85 24
# ℹ 20 more rows# mutate, filter에서 사용하는 경우
mpg %>%
group_by(manufacturer, year) %>%
mutate(N = n()) %>%
filter(n() < 4) %>%
print# A tibble: 18 × 12
# Groups: manufacturer, year [9]
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 jeep grand che… 4 1999 6 auto… 4 15 20 r suv
2 jeep grand che… 4.7 1999 8 auto… 4 14 17 r suv
3 land rover range rov… 4 1999 8 auto… 4 11 15 p suv
4 land rover range rov… 4.2 2008 8 auto… 4 12 18 r suv
5 land rover range rov… 4.4 2008 8 auto… 4 12 18 r suv
6 land rover range rov… 4.6 1999 8 auto… 4 11 15 p suv
7 lincoln navigator… 5.4 1999 8 auto… r 11 17 r suv
8 lincoln navigator… 5.4 1999 8 auto… r 11 16 p suv
9 lincoln navigator… 5.4 2008 8 auto… r 12 18 r suv
10 mercury mountaine… 4 1999 6 auto… 4 14 17 r suv
11 mercury mountaine… 4 2008 6 auto… 4 13 19 r suv
12 mercury mountaine… 4.6 2008 8 auto… 4 13 19 r suv
13 mercury mountaine… 5 1999 8 auto… 4 13 17 r suv
14 pontiac grand prix 3.1 1999 6 auto… f 18 26 r mids…
15 pontiac grand prix 3.8 1999 6 auto… f 16 26 p mids…
16 pontiac grand prix 3.8 1999 6 auto… f 17 27 r mids…
17 pontiac grand prix 3.8 2008 6 auto… f 18 28 r mids…
18 pontiac grand prix 5.3 2008 8 auto… f 16 25 p mids…
# ℹ 1 more variable: N <int>9.3.10 부가 기능
위에서 소개한 dplyr 패키지의 기본 동사 함수를 조금 더 효율적으로 사용(예: 특정 조건을 만족하는 두 개 이상의 변수에 함수 적용)하기 위한 범위 지정 함수로서 아래와 같은 부사(adverb), 접속사 또는 전치사가 본 동사 뒤에 붙음
*_all: 모든 변수에 적용*_at:vars()함수를 이용해 선택한 변수에 적용*_if: 조건식 또는 조건 함수로 선택한 변수에 적용
여기서
*= {filter,arrange,select,rename,mutate,transmute,summarise,group_by}적용할 변수들은 대명사(pronoun)로 지칭되며,
.로 나타냄vars()는*_at계열 함수 내에서 변수를 선택해주는 함수로select()함수와 동일한 문법으로 사용 가능(단독으로는 사용하지 않음)
filter_all(), filter_at(), filter_if()
filter_all():all_vars()또는any_vars()라는 조건 함수와 같이 사용되며, 해당 함수 내에 변수는 대명사.로 나타냄filter_at(): 변수 선택 지시자vars()와vars()에서 선택한 변수에 적용할 조건식 또는 조건 함수를 인수로 받음. 조건식 설정 시vars()에 포함된 변수들은 대명사.으로 표시filter_if(): 조건을 만족하는 변수들을 선택한 후, 선택한 변수들 중 모두 또는 하나라도 입력한 조건을 만족하는 행 추출
# mtcars 데이터셋 사용
## filter_all()
### 모든 변수들이 100 보다 큰 케이스 추출
mtcars %>%
filter_all(all_vars(. > 100)) %>%
print [1] mpg cyl disp hp drat wt qsec vs am gear carb
<0 행> <또는 row.names의 길이가 0입니다>### 모든 변수들 중 하나라도 300 보다 큰 케이스 추출
mtcars %>%
filter_all(any_vars(. > 300)) %>%
print mpg cyl disp hp drat wt qsec vs am gear carb
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Duster 360 14.3 8 360 245 3.21 3.570 15.84 0 0 3 4
Cadillac Fleetwood 10.4 8 472 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440 230 3.23 5.345 17.42 0 0 3 4
Dodge Challenger 15.5 8 318 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400 175 3.08 3.845 17.05 0 0 3 2
Ford Pantera L 15.8 8 351 264 4.22 3.170 14.50 0 1 5 4
Maserati Bora 15.0 8 301 335 3.54 3.570 14.60 0 1 5 8## filter_at()
### 기어 개수(gear)와 기화기 개수(carb)가 짝수인 케이스만 추출
mtcars %>%
filter_at(vars(gear, carb),
~ . %% 2 == 0) %>% # 대명사 앞에 ~ 표시를 꼭 사용해야 함
print mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2## filter_if()
### 내림한 값이 원래 값과 같은 변수들 모두 0이 아닌 케이스 추출
mtcars %>%
filter_if(~ all(floor(.) == .),
all_vars(. != 0)) %>%
# filter_if(~ all(floor(.) == .),
# ~ . != 0) %>%
print mpg cyl disp hp drat wt qsec vs am gear carb
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2select_all(), select_at(), select_if()
변수 선택과 변수명 변경을 동시에 수행
# select_all() 예시
## mpg 데이터셋의 모든 변수명을 대문자로 변경
mpg %>%
select_all(~toupper(.)) %>%
print# A tibble: 234 × 11
MANUFACTURER MODEL DISPL YEAR CYL TRANS DRV CTY HWY FL CLASS
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto… f 18 29 p comp…
2 audi a4 1.8 1999 4 manu… f 21 29 p comp…
3 audi a4 2 2008 4 manu… f 20 31 p comp…
4 audi a4 2 2008 4 auto… f 21 30 p comp…
5 audi a4 2.8 1999 6 auto… f 16 26 p comp…
6 audi a4 2.8 1999 6 manu… f 18 26 p comp…
7 audi a4 3.1 2008 6 auto… f 18 27 p comp…
8 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
9 audi a4 quattro 1.8 1999 4 auto… 4 16 25 p comp…
10 audi a4 quattro 2 2008 4 manu… 4 20 28 p comp…
# ℹ 224 more rows# select_if() 예시
## 문자형 변수를 선택하고 선택한 변수의 이름을 대문자로 변경
mpg %>%
select_if(~ is.character(.), ~ toupper(.)) %>%
print# A tibble: 234 × 6
MANUFACTURER MODEL TRANS DRV FL CLASS
<chr> <chr> <chr> <chr> <chr> <chr>
1 audi a4 auto(l5) f p compact
2 audi a4 manual(m5) f p compact
3 audi a4 manual(m6) f p compact
4 audi a4 auto(av) f p compact
5 audi a4 auto(l5) f p compact
6 audi a4 manual(m5) f p compact
7 audi a4 auto(av) f p compact
8 audi a4 quattro manual(m5) 4 p compact
9 audi a4 quattro auto(l5) 4 p compact
10 audi a4 quattro manual(m6) 4 p compact
# ℹ 224 more rows# select_at() 예시
## model에서 cty 까지 변수를 선택하고 선택한 변수명을 대문자로 변경
mpg %>%
select_at(vars(model:cty), ~ toupper(.)) %>%
print# A tibble: 234 × 7
MODEL DISPL YEAR CYL TRANS DRV CTY
<chr> <dbl> <int> <int> <chr> <chr> <int>
1 a4 1.8 1999 4 auto(l5) f 18
2 a4 1.8 1999 4 manual(m5) f 21
3 a4 2 2008 4 manual(m6) f 20
4 a4 2 2008 4 auto(av) f 21
5 a4 2.8 1999 6 auto(l5) f 16
6 a4 2.8 1999 6 manual(m5) f 18
7 a4 3.1 2008 6 auto(av) f 18
8 a4 quattro 1.8 1999 4 manual(m5) 4 18
9 a4 quattro 1.8 1999 4 auto(l5) 4 16
10 a4 quattro 2 2008 4 manual(m6) 4 20
# ℹ 224 more rowsmutate_all(), mutate_at(), mutate_if()
실제 데이터 전처리 시 가장 많이 사용
mutate_all(): 모든 변수에 적용(모든 데이터가 동일한 데이터 타입인 경우 유용)mutate_at(): 선택한 변수에 적용.vars()함수로 선택mutate_if(): 특정 조건을 만족하는 변수에 적용
# mutate_all() 예시
## 문자형 변수를 선택 후 모든 변수를 요인형으로 변환
mpg %>%
select_if(~is.character(.)) %>%
mutate_all(~factor(.)) %>%
head %>%
print# A tibble: 6 × 6
manufacturer model trans drv fl class
<fct> <fct> <fct> <fct> <fct> <fct>
1 audi a4 auto(l5) f p compact
2 audi a4 manual(m5) f p compact
3 audi a4 manual(m6) f p compact
4 audi a4 auto(av) f p compact
5 audi a4 auto(l5) f p compact
6 audi a4 manual(m5) f p compact# mutate_at() 예시
## cty, hwy 단위를 km/l로 변경
mpg %>%
mutate_at(vars(cty, hwy),
~ . * kpl) %>% # 원래 변수를 변경
head %>%
print# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <dbl> <dbl> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 7.65 12.3 p compa…
2 audi a4 1.8 1999 4 manual(m5) f 8.92 12.3 p compa…
3 audi a4 2 2008 4 manual(m6) f 8.50 13.2 p compa…
4 audi a4 2 2008 4 auto(av) f 8.92 12.7 p compa…
5 audi a4 2.8 1999 6 auto(l5) f 6.80 11.0 p compa…
6 audi a4 2.8 1999 6 manual(m5) f 7.65 11.0 p compa…## "m"으로 시작하거나 "s"로 끝나는 변수 선택 후 요인형으로 변환
mpg %>%
mutate_at(vars(starts_with("m"),
ends_with("s")),
~ factor(.)) %>%
summary manufacturer model displ year
dodge :37 caravan 2wd : 11 Min. :1.600 Min. :1999
toyota :34 ram 1500 pickup 4wd: 10 1st Qu.:2.400 1st Qu.:1999
volkswagen:27 civic : 9 Median :3.300 Median :2004
ford :25 dakota pickup 4wd : 9 Mean :3.472 Mean :2004
chevrolet :19 jetta : 9 3rd Qu.:4.600 3rd Qu.:2008
audi :18 mustang : 9 Max. :7.000 Max. :2008
(Other) :74 (Other) :177
cyl trans drv cty
Min. :4.000 auto(l4) :83 Length:234 Min. : 9.00
1st Qu.:4.000 manual(m5):58 Class :character 1st Qu.:14.00
Median :6.000 auto(l5) :39 Mode :character Median :17.00
Mean :5.889 manual(m6):19 Mean :16.86
3rd Qu.:8.000 auto(s6) :16 3rd Qu.:19.00
Max. :8.000 auto(l6) : 6 Max. :35.00
(Other) :13
hwy fl class
Min. :12.00 Length:234 2seater : 5
1st Qu.:18.00 Class :character compact :47
Median :24.00 Mode :character midsize :41
Mean :23.44 minivan :11
3rd Qu.:27.00 pickup :33
Max. :44.00 subcompact:35
suv :62 # mutate_if() 예시
## 문자형 변수를 요인형으로 변환
mpg %>%
mutate_if(~ is.character(.), ~ factor(.)) %>%
summary manufacturer model displ year
dodge :37 caravan 2wd : 11 Min. :1.600 Min. :1999
toyota :34 ram 1500 pickup 4wd: 10 1st Qu.:2.400 1st Qu.:1999
volkswagen:27 civic : 9 Median :3.300 Median :2004
ford :25 dakota pickup 4wd : 9 Mean :3.472 Mean :2004
chevrolet :19 jetta : 9 3rd Qu.:4.600 3rd Qu.:2008
audi :18 mustang : 9 Max. :7.000 Max. :2008
(Other) :74 (Other) :177
cyl trans drv cty hwy
Min. :4.000 auto(l4) :83 4:103 Min. : 9.00 Min. :12.00
1st Qu.:4.000 manual(m5):58 f:106 1st Qu.:14.00 1st Qu.:18.00
Median :6.000 auto(l5) :39 r: 25 Median :17.00 Median :24.00
Mean :5.889 manual(m6):19 Mean :16.86 Mean :23.44
3rd Qu.:8.000 auto(s6) :16 3rd Qu.:19.00 3rd Qu.:27.00
Max. :8.000 auto(l6) : 6 Max. :35.00 Max. :44.00
(Other) :13
fl class
c: 1 2seater : 5
d: 5 compact :47
e: 8 midsize :41
p: 52 minivan :11
r:168 pickup :33
subcompact:35
suv :62 summarise_all(), summarise_at(), summarise_if()
- 사용 방법은
mutate_all,mutate_at,mutate_all과 동일- 다중 변수 요약 시 코드를 효율적으로 작성할 수 있음.
# summary_all() 예시
## 모든 변수의 최솟값과 최댓값 요약
## 문자형 변수는 알파벳 순으로 최솟값과 최댓값 반환
## 복수의 함수를 적용 시 list()함수 사용
mpg %>%
summarise_all(list(min = ~ min(.),
max = ~ max(.))) %>%
glimpseRows: 1
Columns: 22
$ manufacturer_min <chr> "audi"
$ model_min <chr> "4runner 4wd"
$ displ_min <dbl> 1.6
$ year_min <int> 1999
$ cyl_min <int> 4
$ trans_min <chr> "auto(av)"
$ drv_min <chr> "4"
$ cty_min <int> 9
$ hwy_min <int> 12
$ fl_min <chr> "c"
$ class_min <chr> "2seater"
$ manufacturer_max <chr> "volkswagen"
$ model_max <chr> "toyota tacoma 4wd"
$ displ_max <dbl> 7
$ year_max <int> 2008
$ cyl_max <int> 8
$ trans_max <chr> "manual(m6)"
$ drv_max <chr> "r"
$ cty_max <int> 35
$ hwy_max <int> 44
$ fl_max <chr> "r"
$ class_max <chr> "suv"# summary_at() 예시
## dipl, cyl, cty, hwy에 대해 제조사 별 n수와 평균과 표준편차 계산
mpg %>%
add_count(manufacturer) %>% # 행 집계 결과를 열 변수로 추가하는 함수
group_by(manufacturer, n) %>%
summarise_at(vars(displ, cyl, cty:hwy),
list(mean = ~ mean(.),
sd = ~ sd(.))) %>%
print# A tibble: 15 × 10
# Groups: manufacturer [15]
manufacturer n displ_mean cyl_mean cty_mean hwy_mean displ_sd cyl_sd
<chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 audi 18 2.54 5.22 17.6 26.4 0.673 1.22
2 chevrolet 19 5.06 7.26 15 21.9 1.37 1.37
3 dodge 37 4.38 7.08 13.1 17.9 0.868 1.12
4 ford 25 4.54 7.2 14 19.4 0.541 1
5 honda 9 1.71 4 24.4 32.6 0.145 0
6 hyundai 14 2.43 4.86 18.6 26.9 0.365 1.03
7 jeep 8 4.58 7.25 13.5 17.6 1.02 1.04
8 land rover 4 4.3 8 11.5 16.5 0.258 0
9 lincoln 3 5.4 8 11.3 17 0 0
10 mercury 4 4.4 7 13.2 18 0.490 1.15
11 nissan 13 3.27 5.54 18.1 24.6 0.864 1.20
12 pontiac 5 3.96 6.4 17 26.4 0.808 0.894
13 subaru 14 2.46 4 19.3 25.6 0.109 0
14 toyota 34 2.95 5.12 18.5 24.9 0.931 1.32
15 volkswagen 27 2.26 4.59 20.9 29.2 0.443 0.844
# ℹ 2 more variables: cty_sd <dbl>, hwy_sd <dbl># summary_if() 예시
## 1) 문자형 변수이거나 모든 값이 1999보다 크거나 같은 변수이거나
## 8보다 작거나 같고 정수인 변수를 factor 변환
## 2) 수치형 변수에 대한 제조사 별 n, 평균, 표준편차를 구한 후
## 3) 평균 cty (cty_mean) 기준 내림차순으로 정렬
mpg %>%
mutate_if(~ is.character(.) | all(. >= 1999) |
(all(. <= 8) & is.integer(.)),
~ factor(.)) %>%
add_count(manufacturer) %>%
group_by(manufacturer, n) %>%
summarise_if(~ is.numeric(.),
list(mean = ~ mean(.),
sd = ~ sd(.))) %>%
arrange(desc(cty_mean)) %>%
print# A tibble: 15 × 8
# Groups: manufacturer [15]
manufacturer n displ_mean cty_mean hwy_mean displ_sd cty_sd hwy_sd
<fct> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 honda 9 1.71 24.4 32.6 0.145 1.94 2.55
2 volkswagen 27 2.26 20.9 29.2 0.443 4.56 5.32
3 subaru 14 2.46 19.3 25.6 0.109 0.914 1.16
4 hyundai 14 2.43 18.6 26.9 0.365 1.50 2.18
5 toyota 34 2.95 18.5 24.9 0.931 4.05 6.17
6 nissan 13 3.27 18.1 24.6 0.864 3.43 5.09
7 audi 18 2.54 17.6 26.4 0.673 1.97 2.18
8 pontiac 5 3.96 17 26.4 0.808 1 1.14
9 chevrolet 19 5.06 15 21.9 1.37 2.92 5.11
10 ford 25 4.54 14 19.4 0.541 1.91 3.33
11 jeep 8 4.58 13.5 17.6 1.02 2.51 3.25
12 mercury 4 4.4 13.2 18 0.490 0.5 1.15
13 dodge 37 4.38 13.1 17.9 0.868 2.49 3.57
14 land rover 4 4.3 11.5 16.5 0.258 0.577 1.73
15 lincoln 3 5.4 11.3 17 0 0.577 1 9.3.11 데이터 연결
분석용 데이터를 만들기 위해 연관된 복수의 데이터 테이블을 결합하는 작업이 필수임
서로 연결 또는 연관된 데이터를 관계형 데이터(relational data)라고 칭함
관계는 항상 한 쌍의 데이터 테이블 간의 관계로 정의
관계형 데이터 작업을 위해 설계된 3 가지 “동사” 유형
- Mutating join: 두 데이터 프레임 결합 시 두 테이블 간 행이 일치하는 경우 첫 번째 테이블에 새로운 변수 추가
- Filtering join: 다른 테이블의 관측치와 일치 여부에 따라 데이터 테이블의 행을 필터링
- Set operation: 데이터 셋의 관측치를 집합 연산으로 조합
- R base 패키지에서 제공하는
merge()함수로 mutating join에 해당하는 두 데이터 간 병합이 가능하지만 앞으로 배울*_join()로도 동일한 기능을 수행할 수 있고, 다음과 같은 장점을 가짐
- 행 순서를 보존
merge()에 비해 코드가 직관적이고 빠름
예제
- 데이터:
nycflights13(2013년 미국 New York에서 출발하는 항공기 이착륙 기록 데이터) flights,airlines,airports,planes,weather총 5 개의 데이터 프레임으로 구성되어 있으며, 데이터 구조와 코드북은 다음과 같음
# install.packages("nycflights13")
require(nycflights13)필요한 패키지를 로딩중입니다: nycflights13flights: 336,776 건의 비행에 대한 기록과 19개의 변수로 구성되어 있는 데이터셋
# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>| 변수 | 설명 |
|---|---|
| year, month, day | 출발년도, 월, 일 |
| dep_time, arr_time | 실제 출발-도착 시간(현지시각) |
| sched_dep_time, sched_arr_time | 예정 출발-도착 시간(현지시각) |
| dep_delay, arr_delay | 출발 및 도착 지연 시간(분, min) |
| carrier | 항공코드 약어(두개 문자) |
| tailnum | 비행기 일련 번호 |
| flight | 항공편 번호 |
| origin, dest | 최초 출발지, 목적지 |
| air_time | 비행 시간(분, min) |
| distance | 비행 거리(마일, mile) |
| hour, minutes | 예정 출발 시각(시, 분)으로 분리 |
| time_hour | POSIXct 포맷으로로 기록된 예정 항공편 날짜 및 시간 |
airlines: 항공사 이름 및 약어 정보로 구성
# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. airports: 각 공항에 대한 정보를 포함한 데이터셋이고faa는 공항 코드
# A tibble: 1,458 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/…
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/…
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/…
4 06N Randall Airport 41.4 -74.4 523 -5 A America/…
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/…
6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/…
7 0G6 Williams County Airport 41.5 -84.5 730 -5 A America/…
8 0G7 Finger Lakes Regional Airport 42.9 -76.8 492 -5 A America/…
9 0P2 Shoestring Aviation Airfield 39.8 -76.6 1000 -5 U America/…
10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/…
# ℹ 1,448 more rows| 변수 | 설명 |
|---|---|
| faa | FAA 공항 코드 |
| name | 공항 명칭 |
| lat | 위도 |
| lon | 경도 |
| alt | 고도 |
| tz | 타임존 차이(GMT로부터) |
| dst | 일광 절약 시간제(섬머타임): A=미국 표준 DST, U=unknown, N=no DST |
| tzone | IANA 타임존 |
planes: 항공기 정보(제조사, 일련번호, 유형 등)에 대한 정보를 포함한 데이터셋
# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rows| 변수 | 설명 |
|---|---|
| tailnum | 항공기 일련번호 |
| year | 제조년도 |
| type | 항공기 유형 |
| manufacturer | 제조사 |
| model | 모델명 |
| engines | 엔진 개수 |
| seats | 좌석 수 |
| speed | 속력 |
| engine | 엔진 유형 |
weather: 뉴욕시 각 공항 별 날씨 정보
# A tibble: 26,115 × 15
origin year month day hour temp dewp humid wind_dir wind_speed
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
# ℹ 26,105 more rows
# ℹ 5 more variables: wind_gust <dbl>, precip <dbl>, pressure <dbl>,
# visib <dbl>, time_hour <dttm>| 변수 | 설명 |
|---|---|
| origin | 기상관측소 |
| year, month, day, hour | 년도, 월, 일, 시간 |
| temp, dewp | 기온, 이슬점 (F) |
| humid | 습도 |
| wind_dir, wind_speed, wind_gust | 바람방향(degree), 풍속 및 돌풍속도(mph) |
| precip | 강수량(inch) |
| pressure | 기압(mbar) |
| visib | 가시거리(mile) |
| time_hour | POSIXct 포맷 일자 및 시간 |
열거한 각 테이블은 한 개 또는 복수의 변수로 연결 가능
flights\(\longleftrightarrow\)planes(bytailnum)flights\(\longleftrightarrow\)airlines(bycarrier)flights\(\longleftrightarrow\)airports(byorigin,dest)flights\(\longleftrightarrow\)weather(byorigin,year,month,day,hour)
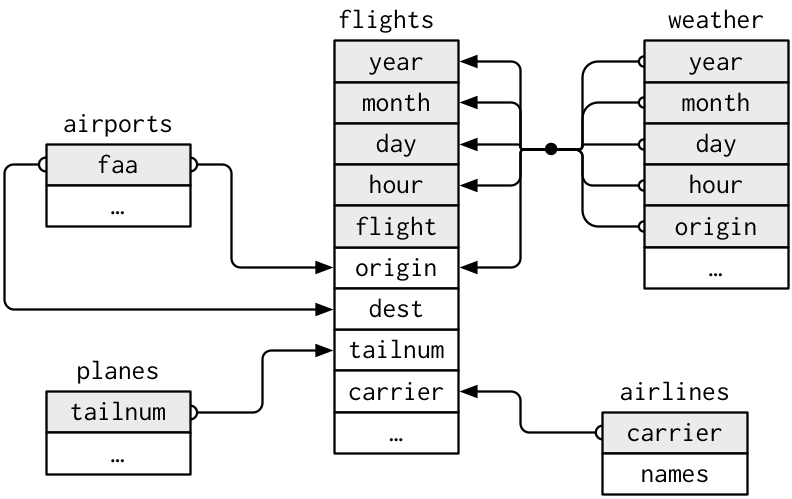
Figure 9.7: NYC flight 2013 데이터 관계도(https://r4ds.had.co.nz/ 에서 발췌)
- 각 쌍의 데이터를 연결하는데 사용한 변수를 키(key)라고 지칭
- 기준 테이블(여기서는
flights데이터셋)의 키 \(\rightarrow\) 기본키(primary key) - 병합할 테이블의 키 \(\rightarrow\) 외래키(foreign key)
- 다수의 변수를 이용한 기본키 및 외래키 생성 가능
- 기준 테이블(여기서는
inner_join
두 데이터셋 모두에 존재하는 키 변수가 일치하는 행을 기준으로 병합
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
inner_join(x, y, by = "key") %>% print# A tibble: 2 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2 left_join()
두 데이터셋 관계 중 왼쪽(
x) 데이터셋의 행은 모두 보존
left_join(x, y, by = "key") %>% print# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA> right_join()
두 데이터셋 관계 중 오른쪽(
y) 데이터셋의 행은 모두 보존
right_join(x, y, by = "key") %>% print# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 4 <NA> y3 full_join
두 데이터셋의 관측치 모두를 보존
full_join(x, y, by = "key") %>% print# A tibble: 4 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
4 4 <NA> y3 9.3.11.1 NYC flights 2013 데이터 join 예시
# flights 데이터 간소화(일부 열만 추출)
flights2 <- flights %>%
select(year:day, hour, origin, dest, tailnum, carrier)
# flights2 와 airlines 병합
flights2 %>%
left_join(airlines, by = "carrier") %>%
print# A tibble: 336,776 × 9
year month day hour origin dest tailnum carrier name
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr>
1 2013 1 1 5 EWR IAH N14228 UA United Air Lines Inc.
2 2013 1 1 5 LGA IAH N24211 UA United Air Lines Inc.
3 2013 1 1 5 JFK MIA N619AA AA American Airlines Inc.
4 2013 1 1 5 JFK BQN N804JB B6 JetBlue Airways
5 2013 1 1 6 LGA ATL N668DN DL Delta Air Lines Inc.
6 2013 1 1 5 EWR ORD N39463 UA United Air Lines Inc.
7 2013 1 1 6 EWR FLL N516JB B6 JetBlue Airways
8 2013 1 1 6 LGA IAD N829AS EV ExpressJet Airlines Inc.
9 2013 1 1 6 JFK MCO N593JB B6 JetBlue Airways
10 2013 1 1 6 LGA ORD N3ALAA AA American Airlines Inc.
# ℹ 336,766 more rows# flights2와 airline, airports 병합
## airports 데이터 간소화
airports2 <- airports %>%
select(faa:name, airport_name = name) %>%
print# A tibble: 1,458 × 2
faa airport_name
<chr> <chr>
1 04G Lansdowne Airport
2 06A Moton Field Municipal Airport
3 06C Schaumburg Regional
4 06N Randall Airport
5 09J Jekyll Island Airport
6 0A9 Elizabethton Municipal Airport
7 0G6 Williams County Airport
8 0G7 Finger Lakes Regional Airport
9 0P2 Shoestring Aviation Airfield
10 0S9 Jefferson County Intl
# ℹ 1,448 more rowsflights2 %>%
left_join(airlines, by = "carrier") %>%
left_join(airports2, by = c("origin" = "faa")) %>%
print# A tibble: 336,776 × 10
year month day hour origin dest tailnum carrier name airport_name
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 2013 1 1 5 EWR IAH N14228 UA United Air… Newark Libe…
2 2013 1 1 5 LGA IAH N24211 UA United Air… La Guardia
3 2013 1 1 5 JFK MIA N619AA AA American A… John F Kenn…
4 2013 1 1 5 JFK BQN N804JB B6 JetBlue Ai… John F Kenn…
5 2013 1 1 6 LGA ATL N668DN DL Delta Air … La Guardia
6 2013 1 1 5 EWR ORD N39463 UA United Air… Newark Libe…
7 2013 1 1 6 EWR FLL N516JB B6 JetBlue Ai… Newark Libe…
8 2013 1 1 6 LGA IAD N829AS EV ExpressJet… La Guardia
9 2013 1 1 6 JFK MCO N593JB B6 JetBlue Ai… John F Kenn…
10 2013 1 1 6 LGA ORD N3ALAA AA American A… La Guardia
# ℹ 336,766 more rows# flights2와 airline, airports, planes 병합
planes2 <- planes %>%
select(tailnum, model)
flights2 %>%
left_join(airlines, by = "carrier") %>%
left_join(airports2, by = c("origin" = "faa")) %>%
left_join(planes2, by = "tailnum") %>%
print# A tibble: 336,776 × 11
year month day hour origin dest tailnum carrier name airport_name model
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 2013 1 1 5 EWR IAH N14228 UA Unit… Newark Libe… 737-…
2 2013 1 1 5 LGA IAH N24211 UA Unit… La Guardia 737-…
3 2013 1 1 5 JFK MIA N619AA AA Amer… John F Kenn… 757-…
4 2013 1 1 5 JFK BQN N804JB B6 JetB… John F Kenn… A320…
5 2013 1 1 6 LGA ATL N668DN DL Delt… La Guardia 757-…
6 2013 1 1 5 EWR ORD N39463 UA Unit… Newark Libe… 737-…
7 2013 1 1 6 EWR FLL N516JB B6 JetB… Newark Libe… A320…
8 2013 1 1 6 LGA IAD N829AS EV Expr… La Guardia CL-6…
9 2013 1 1 6 JFK MCO N593JB B6 JetB… John F Kenn… A320…
10 2013 1 1 6 LGA ORD N3ALAA AA Amer… La Guardia <NA>
# ℹ 336,766 more rows# flights2와 airline, airports2, planes2, weather2 병합
## weather 데이터 간소화
weather2 <- weather %>%
select(origin:temp, wind_speed)
flights2 %>%
left_join(airlines, by = "carrier") %>%
left_join(airports2, by = c("origin" = "faa")) %>%
left_join(planes2, by = "tailnum") %>%
left_join(weather2, by = c("origin", "year",
"month", "day", "hour")) %>%
glimpseRows: 336,776
Columns: 13
$ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 201…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6, …
$ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA", "…
$ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD", "…
$ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N39463…
$ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "AA…
$ name <chr> "United Air Lines Inc.", "United Air Lines Inc.", "Americ…
$ airport_name <chr> "Newark Liberty Intl", "La Guardia", "John F Kennedy Intl…
$ model <chr> "737-824", "737-824", "757-223", "A320-232", "757-232", "…
$ temp <dbl> 39.02, 39.92, 39.02, 39.02, 39.92, 39.02, 37.94, 39.92, 3…
$ wind_speed <dbl> 12.65858, 14.96014, 14.96014, 14.96014, 16.11092, 12.6585…9.3.12 확장 예제: Gapminder
gapminder (Bryan 2017)는 1950 ~ 2007 년 까지 5년 단위의 국가별 인구(population), 기대수명(year), 일인당 국민 총소득(gross domestic product per captia, 달러)에 대한 데이터를 제공 하지만, 본 강의에서는 현재 Gapminder 사이트에서 직접 다운로드 받은 가장 최근 데이터를 가지고 dplyr 패키지의 기본 동사를 학습함과 동시에 최종적으로 gapminder 패키지에서 제공하는 데이터와 동일한 형태의 구조를 갖는 데이터를 생성하는 것이 목직임. 해당 데이터는 github 계정에서 다운로드가 가능함.
gapminder-exercise.xlsx는 총 4개의 시트로 구성되어 있으며, 각 시트에 대한 설명은 아래와 같음.
| 시트 이름 | 설명 |
|---|---|
| region | 국가별 지역 정보 포함 |
| country_pop | 국가별 1800 ~ 2100년 까지 추계 인구수(명) |
| gdpcap | 국가별 1800 ~ 2100년 까지 국민 총소득(달러) |
| lifeexp | 국가별 1800 ~ 2100년 까지 기대수명(세) |
Prerequisites
gapminder패키지 설치하기
install.packages("gapminder")readxl패키지 +%>%를 이용해 Gapminder 데이터(gapminder-exercise.xlsx) 불러오기
require(readxl)필요한 패키지를 로딩중입니다: readxlrequire(gapminder)필요한 패키지를 로딩중입니다: gapminderWarning in library(package, lib.loc = lib.loc, character.only = TRUE,
logical.return = TRUE, : 'gapminder'이라고 불리는 패키지가 없습니다path <- "dataset/gapminder/gapminder-exercise.xlsx"
# base R 문법 적용
# sheet_name <- excel_sheets(path)
# gapmL <- lapply(sheet_name, function(x) read_excel(path = path, sheet = x))
# names(gapmL) <- sheet_name
# pipe 연산자 이용
path %>%
excel_sheets %>%
set_names %>%
map(read_excel, path = path) -> gapmL
# 개별 객체에 데이터 저장
command <- paste(names(gapmL), "<-",
paste0("gapmL$", names(gapmL)))
for (i in 1:length(command)) eval(parse(text = command[i]))
# check
ls() [1] "내용" "동사(함수)" "변수"
[4] "변수명" "변수설명(국문)" "변수설명(영문)"
[7] "설명" "시트 이름" "연비"
[10] "airports2" "audi" "base::merge()"
[13] "by_mpg" "command" "country_pop"
[16] "dd" "def.chunk.hook" "dplyr::*_join()"
[19] "flights2" "gallon" "gapmL"
[22] "gdpcap" "hook_output" "i"
[25] "kpl" "lifeexp" "mile"
[28] "mpg" "mpg_asc" "mpg_sortb"
[31] "mpg_sortt" "mpg_uniq" "mpg_uniq2"
[34] "path" "planes2" "pulse"
[37] "R base 패키지 함수" "region" "slice_mpg"
[40] "slice_mpg_grp" "tab4_01" "tab4_03"
[43] "tab4_04" "tab4_05" "tab4_06"
[46] "tab4_07" "tab4_08" "titanic"
[49] "titanic2" "titanic3" "varn_mpg"
[52] "weather2" "x" "y" region %>% print# A tibble: 234 × 3
iso country region
<chr> <chr> <chr>
1 AFG Afghanistan Southern Asia
2 ALB Albania Southern Europe
3 DZA Algeria Northern Africa
4 ASM American Samoa Polynesia Oceania
5 AND Andorra Southern Europe
6 AGO Angola Middle Africa
7 AIA Anguilla Caribbean America
8 ATG Antigua and Barbuda Caribbean America
9 ARG Argentina South America
10 ARM Armenia Western Asia
# ℹ 224 more rowscountry_pop %>% print# A tibble: 59,297 × 4
iso country year population
<chr> <chr> <dbl> <dbl>
1 afg Afghanistan 1800 3280000
2 afg Afghanistan 1801 3280000
3 afg Afghanistan 1802 3280000
4 afg Afghanistan 1803 3280000
5 afg Afghanistan 1804 3280000
6 afg Afghanistan 1805 3280000
7 afg Afghanistan 1806 3280000
8 afg Afghanistan 1807 3280000
9 afg Afghanistan 1808 3280000
10 afg Afghanistan 1809 3280000
# ℹ 59,287 more rowsgdpcap %>% print# A tibble: 46,995 × 4
iso_code country year gdp_total
<chr> <chr> <dbl> <dbl>
1 afg Afghanistan 1800 1977840000
2 afg Afghanistan 1801 1977840000
3 afg Afghanistan 1802 1977840000
4 afg Afghanistan 1803 1977840000
5 afg Afghanistan 1804 1977840000
6 afg Afghanistan 1805 1977840000
7 afg Afghanistan 1806 1977840000
8 afg Afghanistan 1807 1977840000
9 afg Afghanistan 1808 1977840000
10 afg Afghanistan 1809 1977840000
# ℹ 46,985 more rowslifeexp %>% print# A tibble: 56,130 × 4
country iso_code year life_expectancy
<chr> <chr> <dbl> <dbl>
1 Afghanistan afg 1800 28.2
2 Afghanistan afg 1801 28.2
3 Afghanistan afg 1802 28.2
4 Afghanistan afg 1803 28.2
5 Afghanistan afg 1804 28.2
6 Afghanistan afg 1805 28.2
7 Afghanistan afg 1806 28.2
8 Afghanistan afg 1807 28.1
9 Afghanistan afg 1808 28.1
10 Afghanistan afg 1809 28.1
# ℹ 56,120 more rowscountry_pop,gdpcap,lifeexp데이터 셋 결합
gap_unfilter <- country_pop %>%
left_join(gdpcap, by = c("iso" = "iso_code",
"country",
"year")) %>%
left_join(lifeexp, by = c("iso" = "iso_code",
"country",
"year"))
gap_unfilter %>% print# A tibble: 59,297 × 6
iso country year population gdp_total life_expectancy
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 afg Afghanistan 1800 3280000 1977840000 28.2
2 afg Afghanistan 1801 3280000 1977840000 28.2
3 afg Afghanistan 1802 3280000 1977840000 28.2
4 afg Afghanistan 1803 3280000 1977840000 28.2
5 afg Afghanistan 1804 3280000 1977840000 28.2
6 afg Afghanistan 1805 3280000 1977840000 28.2
7 afg Afghanistan 1806 3280000 1977840000 28.2
8 afg Afghanistan 1807 3280000 1977840000 28.1
9 afg Afghanistan 1808 3280000 1977840000 28.1
10 afg Afghanistan 1809 3280000 1977840000 28.1
# ℹ 59,287 more rows- 인구 수 6만 이상, 1950 ~ 2020년 년도 추출
gap_filter <- gap_unfilter %>%
filter(population >= 60000,
between(year, 1950, 2020))
gap_filter %>% print# A tibble: 13,159 × 6
iso country year population gdp_total life_expectancy
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 afg Afghanistan 1950 7752117 18543063864 32.5
2 afg Afghanistan 1951 7840151 18988845722 32.9
3 afg Afghanistan 1952 7935996 19538422152 33.6
4 afg Afghanistan 1953 8039684 20645908512 34.3
5 afg Afghanistan 1954 8151316 20997790016 35.0
6 afg Afghanistan 1955 8270992 21330888368 35.7
7 afg Afghanistan 1956 8398873 22206620212 36.4
8 afg Afghanistan 1957 8535157 22131662101 37.1
9 afg Afghanistan 1958 8680097 23297380348 37.9
10 afg Afghanistan 1959 8833947 23895826635 38.6
# ℹ 13,149 more rowsiso변수 값을 대문자로 변환하고, 1인당 국민소득(gdp_total/population) 변수gdp_cap생성 후gdp_total제거
gap_filter <- gap_filter %>%
mutate(iso = toupper(iso),
gdp_cap = gdp_total/population) %>%
select(-gdp_total)
gap_filter %>% print # A tibble: 13,159 × 6
iso country year population life_expectancy gdp_cap
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 AFG Afghanistan 1950 7752117 32.5 2392
2 AFG Afghanistan 1951 7840151 32.9 2422
3 AFG Afghanistan 1952 7935996 33.6 2462
4 AFG Afghanistan 1953 8039684 34.3 2568
5 AFG Afghanistan 1954 8151316 35.0 2576
6 AFG Afghanistan 1955 8270992 35.7 2579
7 AFG Afghanistan 1956 8398873 36.4 2644
8 AFG Afghanistan 1957 8535157 37.1 2593
9 AFG Afghanistan 1958 8680097 37.9 2684
10 AFG Afghanistan 1959 8833947 38.6 2705
# ℹ 13,149 more rowsregion데이터셋에서 대륙(region) 변수 결합
gap_filter <- gap_filter %>%
left_join(region %>% select(-country),
by = c("iso"))
gap_filter %>% print# A tibble: 13,159 × 7
iso country year population life_expectancy gdp_cap region
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 AFG Afghanistan 1950 7752117 32.5 2392 Southern Asia
2 AFG Afghanistan 1951 7840151 32.9 2422 Southern Asia
3 AFG Afghanistan 1952 7935996 33.6 2462 Southern Asia
4 AFG Afghanistan 1953 8039684 34.3 2568 Southern Asia
5 AFG Afghanistan 1954 8151316 35.0 2576 Southern Asia
6 AFG Afghanistan 1955 8270992 35.7 2579 Southern Asia
7 AFG Afghanistan 1956 8398873 36.4 2644 Southern Asia
8 AFG Afghanistan 1957 8535157 37.1 2593 Southern Asia
9 AFG Afghanistan 1958 8680097 37.9 2684 Southern Asia
10 AFG Afghanistan 1959 8833947 38.6 2705 Southern Asia
# ℹ 13,149 more rows- 변수 정렬 (
iso,country,region,year:gdp_cap순서로)
gap_filter <- gap_filter %>%
select(iso:country, region, everything())- 문자형 변수를 요인형으로 변환하고,
population을 정수형으로 변환
gap_filter <- gap_filter %>%
mutate_if(~ is.character(.), ~factor(.)) %>%
mutate(population = as.integer(population))- 2-7 절차를 pipe로 묶으면
gap_filter <- country_pop %>%
left_join(gdpcap, by = c("iso" = "iso_code",
"country",
"year")) %>%
left_join(lifeexp, by = c("iso" = "iso_code",
"country",
"year")) %>%
filter(population >= 60000,
between(year, 1950, 2020)) %>%
mutate(iso = toupper(iso),
gdp_cap = gdp_total/population) %>%
select(-gdp_total) %>%
left_join(region %>% select(-country),
by = c("iso")) %>%
select(iso:country, region, everything()) %>%
mutate_if(~ is.character(.), ~factor(.)) %>%
mutate(population = as.integer(population))
# write_csv(gap_filter, "dataset/gapminder/gapminder_filter.csv")- 2020년 현재 지역별 인구수, 평균 일인당 국민소득, 평균 기대수명 계산 후 인구 수로 내림차순 정렬
gap_filter %>%
filter(year == 2020) %>%
group_by(region) %>%
summarise(Population = sum(population),
`GDP/Captia` = mean(gdp_cap),
`Life expect` = mean(life_expectancy, na.rm = TRUE)) %>%
arrange(desc(Population))References
tally의 사전적 의미: calculate the total number of↩︎